BigQueryのクエリ一発で期間データを日別レコードに展開し、歯抜けを補完、さらに正規化する方法をご紹介します。
正規化、というのは使いやすい形に整形する、ということです。
例えば期間データは、他の時系列データと結合してグラフ描画したい時、期間(開始日と終了日)ではなく一日ごとにレコードが分かれていた方が何かと使いやすいわけです。
今回ご紹介する例では、コロナの緊急事態措置・まん延防止等重点措置の対象地域・期間のデータを使っています。
ビフォーアフター
まずは結果から。クエリ一発で以下のように正規化しました。
<ビフォー>

<アフター>

emergencyは緊急事態措置、priorityはまん延防止等重点措置を示しています。
日付は2019-01-01から全都道府県分あります。
これで使いやすくなりました。
それでは、クエリをみていきましょう。
BigQueryで期間(開始日、終了日)データを日別のレコードに展開する
まずは、期間を日別レコードに展開します。これには BigQuery の UNNEST 関数を使います。下のクエリでは 2019-01-01 から本日日付までを1レコードずつ出力します。
| SELECT target_date FROM UNNEST(GENERATE_DATE_ARRAY( DATE(‘2019-01-01’), CURRENT_DATE())) AS target_date |
出力結果
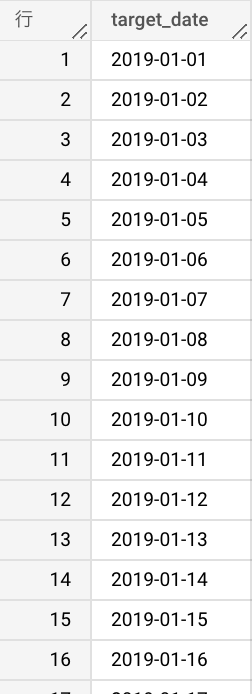
次に、各都道府県(area)ごとに全ての日付が欲しいので、CROSS JOIN で先ほどの日付テーブルと area を結合します。
| WITH date_master AS ( SELECT target_date FROM UNNEST(GENERATE_DATE_ARRAY( DATE(‘2019-01-01’), CURRENT_DATE())) AS target_date ), ori AS ( SELECT * FROM `プロジェクトID.データセット名.テーブル名` ) SELECT target_date, area FROM date_master CROSS JOIN (SELECT DISTINCT area FROM ori) |
出力結果
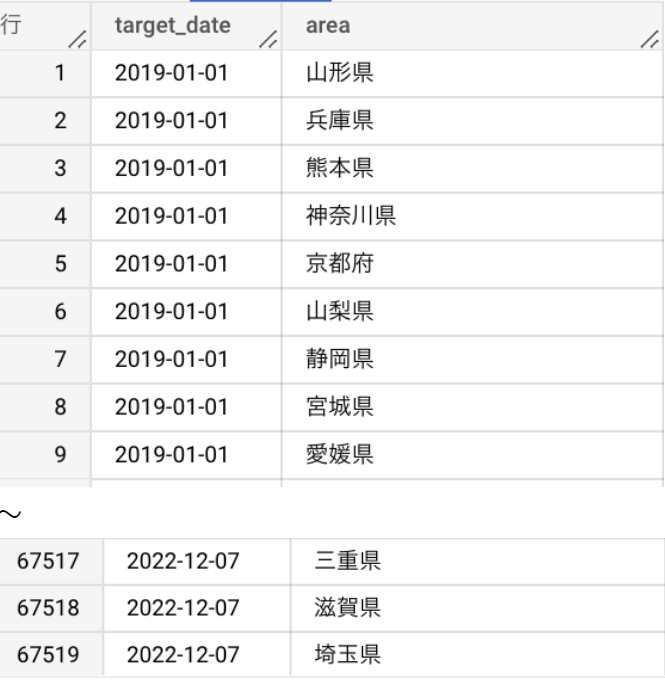
次に、上記のテーブルに、元テーブルを INNER JOIN します。
| WITH date_master AS ( SELECT target_date FROM UNNEST(GENERATE_DATE_ARRAY( DATE(‘2019-01-01’), CURRENT_DATE())) AS target_date ), ori AS ( SELECT * FROM `プロジェクトID.データセット名.テーブル名` ), cro AS ( SELECT target_date, area FROM date_master CROSS JOIN (SELECT DISTINCT area FROM ori) ) SELECT * FROM date_master, ori WHERE date_master.target_date BETWEEN ori.start_date AND ori.end_date ORDER BY target_date |
出力結果
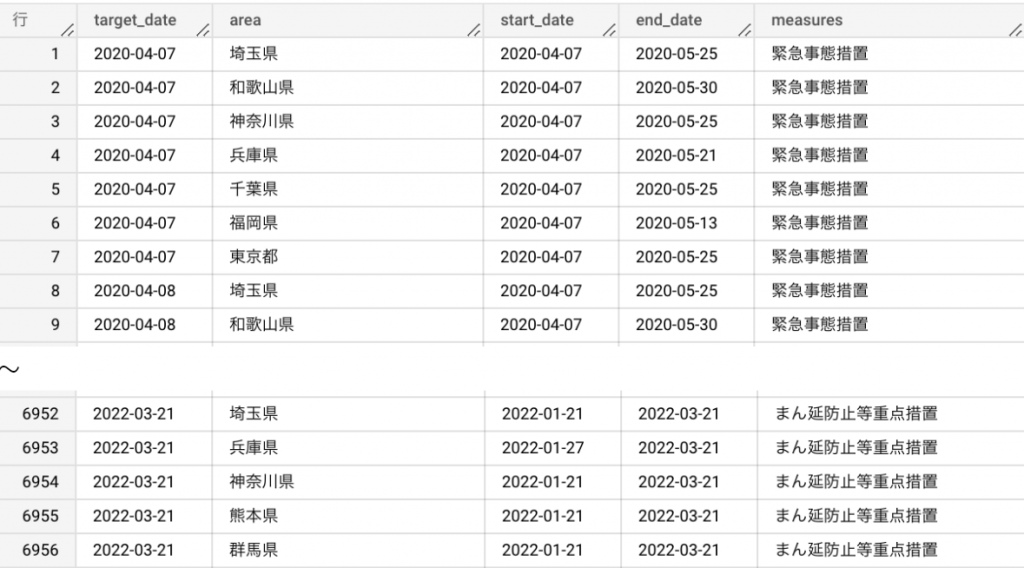
INNER JOIN なので元テーブルの期間外のレコードは消えて歯抜けの状態になっていますが、期間に含まれる日付のレコードが作成できた状態になりました。
最後に、歯抜けの日付を補完し、緊急事態宣言、まん延防止等重点措置をそれぞれカラムにして0,1表記に置き換えます。
最終クエリ
| WITH date_master AS ( SELECT target_date FROM UNNEST(GENERATE_DATE_ARRAY( DATE(‘2019-01-01’), CURRENT_DATE())) AS target_date ), ori AS ( SELECT * FROM `プロジェクトID.データセット名.テーブル名` ), cro AS ( SELECT target_date, area FROM date_master CROSS JOIN (SELECT DISTINCT area FROM ori) ), seq AS ( SELECT * FROM date_master, ori WHERE date_master.target_date BETWEEN ori.start_date AND ori.end_date ) SELECT cro.target_date AS target_date, cro.area, CASE WHEN seq.measures = ‘緊急事態措置’ THEN 1 ELSE 0 END AS emergency, CASE WHEN seq.measures = ‘まん延防止等重点措置’ THEN 1 ELSE 0 END AS priority FROM cro LEFT JOIN seq ON cro.target_date = seq.target_date AND cro.area = seq.area ORDER BY target_date |
出力結果
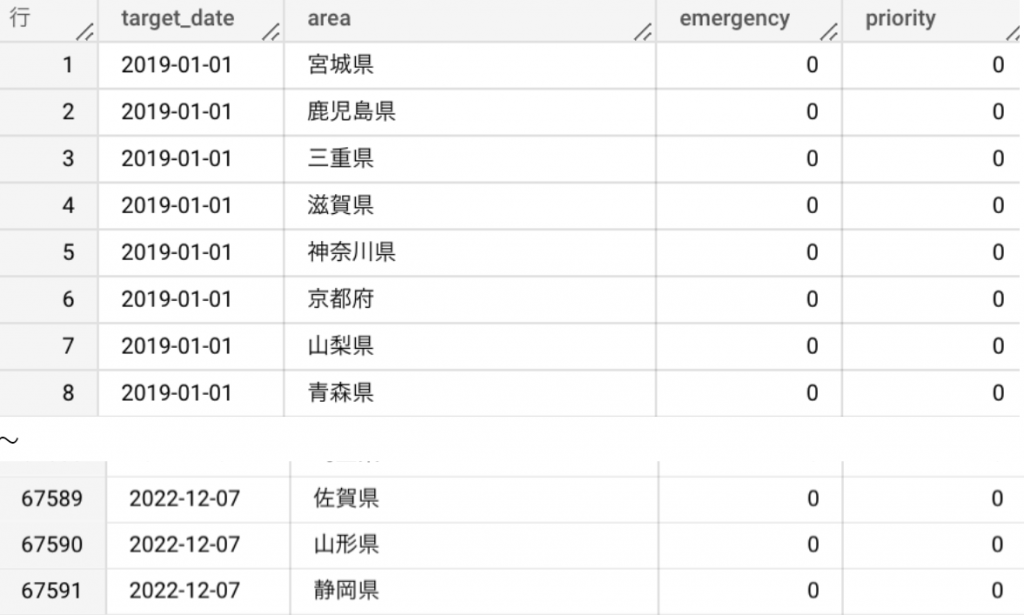
日付の補完のため、全日付と地域をもった 「cro」 に日付、地域をキーにして LEFT JOIN しました。また、0/1に置き換えるために CASE 文を使っています。
これで、機械学習のインプットにしたり、分析で他のデータとくっつけたりグラフ描画したり、使えるデータになりました。クエリ一発でできるので結構便利です。
いかがでしたか。一から書くと手間ですが、色々なデータで応用が効くと思うので良かったら参考にしてください。
まとめ
- UNNEST 関数で期間を1行ずつの日付データに展開する
- CROSS JOIN で 交差結合し、「日付」×「地域」のテーブルを作る
- CASE 関数でデータを正規化(0/1で表す)する
編集後記
緊急事態宣言・まん延防止等重点措置の対象地域と期間について、まとまった情報を探している方もいるかもしれないので、ここで補足しておきます。
元データはどこから持ってきたのか、というと、内閣官房の特設サイト(https://corona.go.jp/emergency/)でPDFを一枚ずつ開いて、文章を読み、対象地域と期間を読み取る、という労力をかけてデータ化しました(白目)