複数の時系列データの波形の類似度を BigQuery のクエリ一発で調べる方法をご紹介します。
だって、ググると CCF やら DTW やらが出てきますが、わざわざ Python で書くのは正直しんどい時とか、あるじゃないですか。
出典:http://www.thothchildren.czzzzzzzom/chapter/59b495f775704408bd43002d
CCF(相互相関関数):2 つの時系列データの各サンプル値間の相関を取る、時間のズレも計算に入れられる
DTW(動的時間伸縮法):CCFに加え周期が伸縮するような時系列データの類似度も計算できる
タイミングのズレはなく、周期の伸縮も考慮しないなら BigQuery の CORR 関数だけで類似度を調べることができます。さらに今回は、複数の比較対象を一発で見比べたい、という(私の)要望に応えるため BigQuery Scripting でループさせました。
時系列データの波形が似ている=相関が高い
いろいろあってビールの家計支出について東京と似た波形(平行トレンド)の地域ってどこ? を知りたくなった、というのが今回の調査の経緯です。その辺は別記事にしたのでよかったら覗いてってください!
まずは結果から。
東京都の波形と相関の高いもの、低いものそれぞれ2つずつピックアップしてみました。

東京と最も相関が高いのは大阪(堺市)というのはなんとなく想像通りでした。
BigQuery のクエリ一発で時系列データの相関係数を一覧出力する方法
BigQuery で FOR/WHILEループや IF文 が書けるのはご存じでしょうか。BigQuery Scripting と言って、クエリ内にスクリプトが書けるという便利機能です。
今回、時系列データの相関係数を出したいということで、日毎の金額について、東京との差が小さい(=相関が高い)かどうかを CORR 関数(ピアソン相関)で調べます。
つまり、一度のクエリで一つの地域しかできません。
なので、クエリ一発で全地域の相関係数を一覧で出力するために、ループ処理の力を借りることにしました。以下がクエリになります。
クエリ全体
# 変数の宣言
DECLARE areas ARRAY<STRING>; # areas という配列を作ってループを回します
DECLARE x INT64 DEFAULT 1; # areas で使う引数
DECLARE t STRING DEFAULT ”; # 比較のareas名を格納
DECLARE cor FLOAT64 DEFAULT 0; # 相関係数
# 変数への代入
# ARRAYの値を自動的に作りたかったので、ARRAY_AGGで作成
SET areas = (
SELECT ARRAY_AGG(area_code) as list
FROM (SELECT area_code FROM `プロジェクトID.データセット名.テーブル名` GROUP BY area_code ORDER BY area_code)
);
# 結果格納用の一時テーブル
CREATE OR REPLACE TEMP TABLE _SESSION.tmp(
t STRING,
cor FLOAT64
);
# ループ処理
# areasの長さまで繰り返し
WHILE x <= array_length(areas) DO
# 比較対象の都道府県コードを格納
SET t = areas [ORDINAL(x)];
# 相関係数を格納
SET cor = (
WITH area1 as (
SELECT
area_code, area_name,
CAST(CONCAT(
NORMALIZE(SUBSTR(year_month,0,INSTR(year_month,’年’) – 1),NFKC),
‘-‘,
NORMALIZE(LPAD(TRANSLATE(SUBSTR(year_month,INSTR(year_month,’年’) + 1, 2),’月’,”),2,’0′),NFKC),
‘-01’) as DATE) AS year_month,
CAST(value AS FLOAT64) AS value
FROM `プロジェクトID.データセット名.テーブル名`
WHERE cat01_code = ‘011100030’ –ビール
AND cat02_code = ’03’ — 二人以上の世帯(2000年〜)
AND area_code = ‘13003’ –東京都区部
), area2 as (
SELECT
area_code, area_name,
CAST(CONCAT(
NORMALIZE(SUBSTR(year_month,0,INSTR(year_month,’年’) – 1),NFKC),
‘-‘,
NORMALIZE(LPAD(TRANSLATE(SUBSTR(year_month,INSTR(year_month,’年’) + 1, 2),’月’,”),2,’0′),NFKC),
‘-01’) as DATE) AS year_month,
CAST(value AS FLOAT64) AS value
FROM `プロジェクトID.データセット名.テーブル名`
WHERE cat01_code = ‘011100030’ –ビール
AND cat02_code = ’03’ — 二人以上の世帯(2000年〜)
AND area_code = areas [ORDINAL(x)] # areasのX番目の値を取り出す
)
SELECT
CORR(value1,value2) AS correlation
FROM
(SELECT
area1.value AS value1,
area2.value AS value2,
FROM area1 LEFT JOIN area2 ON area1.year_month = area2.year_month
)
);
# 対象の地域コードと、東京との相関係数を一時テーブルにINSERT
INSERT _SESSION.tmp (
SELECT
t,
cor
);
SET x = x + 1;
END WHILE;
# ループ処理終了
# 時系列データの相関係数一覧で出力
SELECT
c.t,
m.area_name,
c.cor
FROM _SESSION.tmp LEFT JOIN (
SELECT area_code,area_name
FROM `プロジェクトID.データセット名.テーブル名`
GROUP BY area_code,area_name
ORDER BY area_code
) AS m ON c.t = m.area_code
ORDER BY c.cor
出力結果(2019年の月別ビールへの支出額に関する、東京との相関係数)
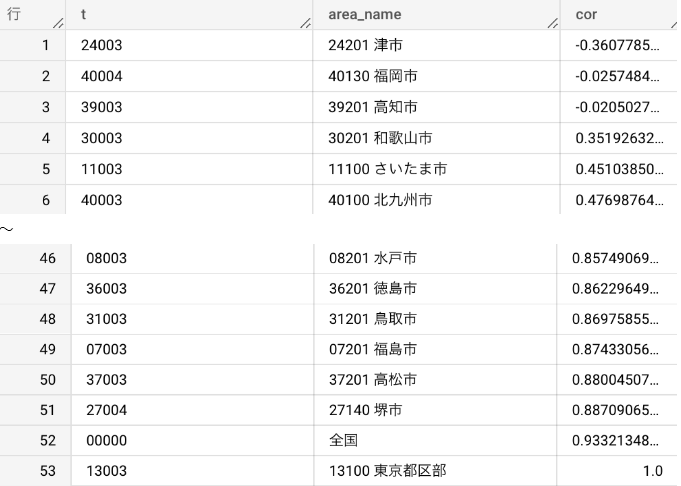
東京自身は相関が1、次に相関が高いのは全国ですが、全国には東京のデータも含まれているので除外し、最も相関の高い地域は堺市(大阪)となりました。
BigQuery Scripting 使ってみた感想
実は、BigQuery Scripting を書いてみたのは今回が初めてでしたが、使ってみてわかりました。めちゃくちゃ便利ですね!
これまでは BigQuery 一発でできない処理は、Vertex AI のワークベンチでノートブック(jupyter notebook的なやつ)を立ち上げて、Python で BigQuery からデータロードしてから処理する、ということをやっていました。
でも、今回のようなちょっとした検証やデータ確認だったら、BigQuery 単体でできる方が素敵ですね。もっと早くに出会いたかった。
まとめ
- 類似度=相関が高い、ということで CORR 関数が使える
- ただし、ズレや伸縮は考慮しない
- 複数の比較対象がある場合は BigQuery Scripting でループさせると便利