
今回はAWS、Google Cloud、Azure の3大クラウドで、データ周りのサービスの価格やカスタマイズ性、処理方式の違いについて、まとめてみました。
なお3大クラウドのサービスのほとんどは従量課金なので料金はデータ量や処理頻度、求めるスペックによるのですが、それだと比較しにくいので大体同じくらいの条件で試算しました。
システムのデータ周りのアーキ選定で頭を悩ませている方に、参考にしていただければと思います。
ETLツールの比較
サービス/プロダクト名の欄に記載している(Apache 〜)は、各プロダクトの中で実際に動いているオープンソースのフレームワークです。
詳しいことは後述しますが、簡単に違いを書くと、Beam は異なる実行環境でのデータ処理パイプラインの移植性に重点を置き、 Airflow はワークフローのスケジューリングと管理に、そして Spark は高速なデータ処理と分析に特化しています。
| クラウド基盤 | サービス/プロダクト名 | 主な利用シーン | 処理方式 | カスタマイズ性 | 料金体系 | 無料枠の有無 | 料金例※ |
|---|---|---|---|---|---|---|---|
| Google Cloud | Cloud Dataflow(Apache Beam) | ・DWHへのデータロード ・機械学習モデルのトレーニング ・リアルタイムデータの分析 | ・バッチ処理 ・ストリーミング処理 | ・コードベース | ・従量課金 | なし | USD 25.92 |
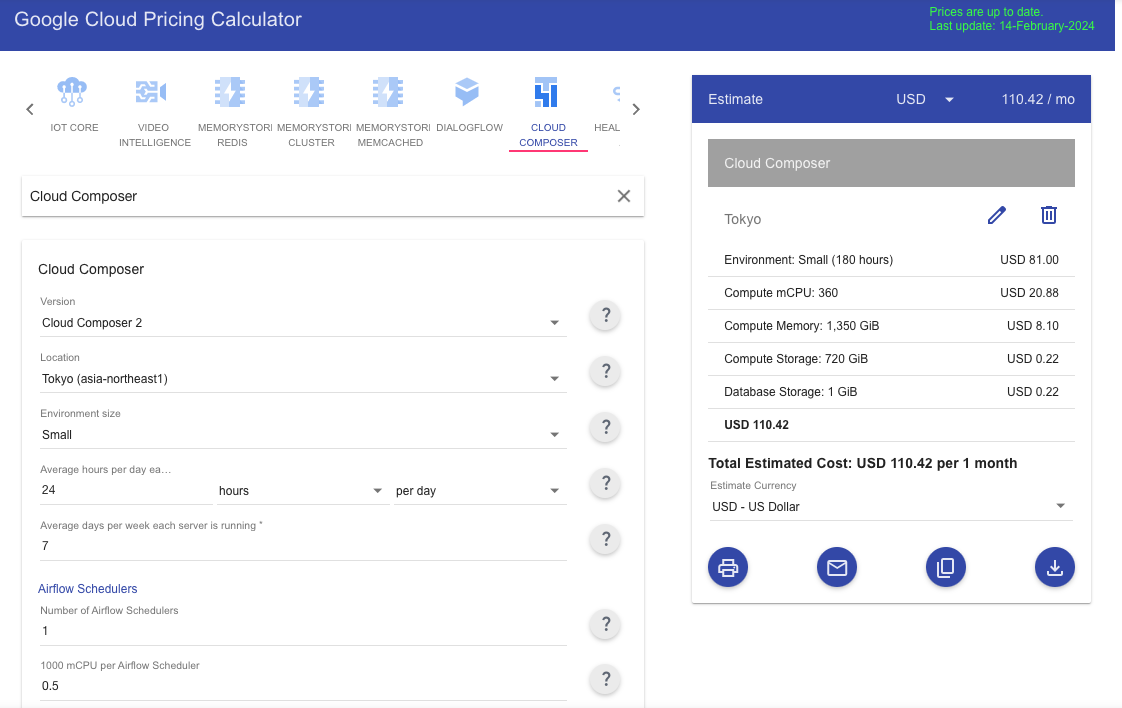
| Cloud Composer(Apache Airflow) | ・定期的なデータ処理 ・イベントドリブンのデータ処理 ・複数のデータソースのデータ統合 | ・バッチ処理 ・ストリーミング処理 | ・コードベース | ・従量課金 ・定額 | なし | USD 110.42 | |
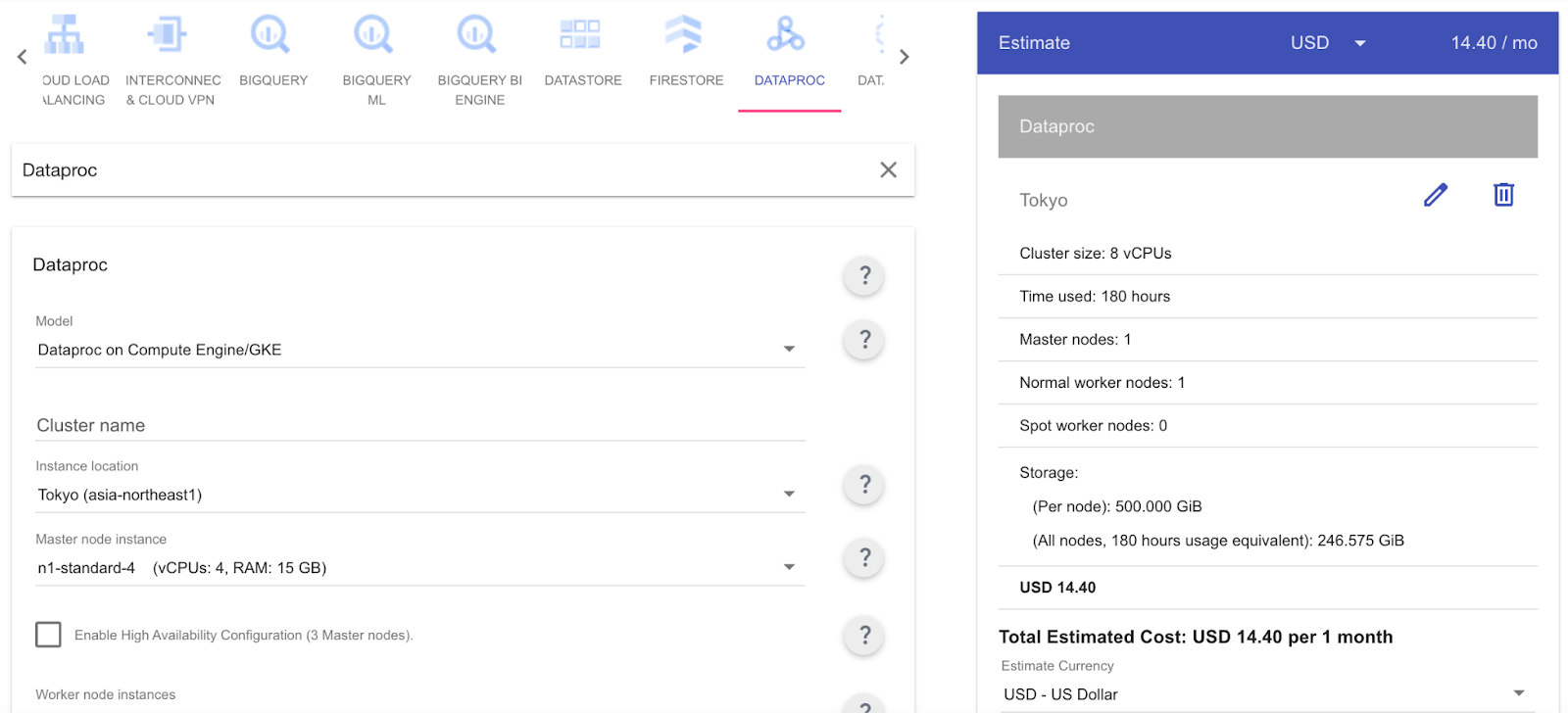
| Dataproc (Apache Spark) | ・ビッグデータ処理 ・ELT/ETL ・データの分析、可視化 ・機械学習 | ・バッチ処理 ・ストリーミング処理 | ・コードベース | ・従量課金 ・定額 | なし | USD 14.40 | |
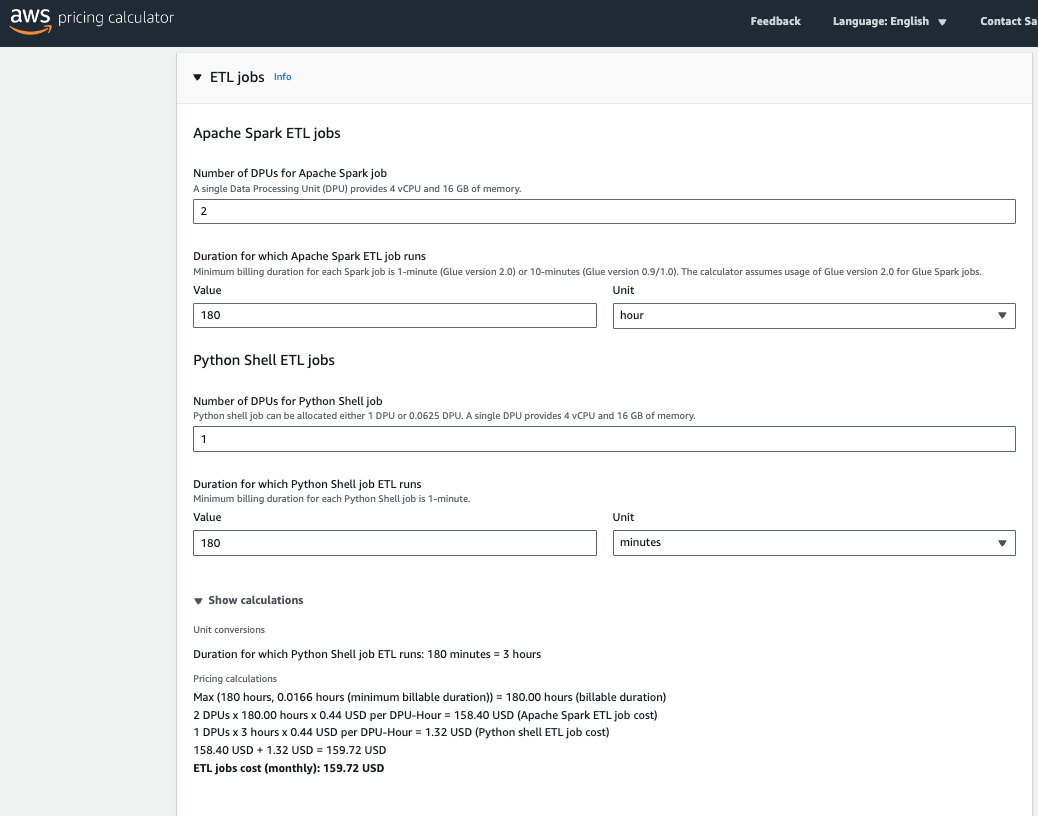
| AWS | Amazon Glue(Apache Spark) | ・オンプレミスからのデータ移行 ・DWHへのデータ統合 ・データの分析、可視化 | ・バッチ処理 ・ストリーミング処理 | ・ノーコード ・コードベース | ・従量課金 ・定額 | なし | USD 159.72 |
| Azure | Azure Data Factory(Apache Airflow) | ・オンプレミスからのデータ移行 ・DWHへのデータ統合 ・データの分析、可視化 | ・バッチ処理 ・ストリーミング処理 | ・ノーコード ・コードベース | ・従量課金 ・定額 | あり 最初の12ヶ月間は5つの低頻度アクティビティが無料 | USD 435.24 |
| その他 | trocco® | ・データの分析、可視化 ・データのマーケティング活用 | ・バッチ処理 ・ストリーミング処理 | ・ノーコード | ・従量課金 | あり 1日100万レコード | Free:無料 Light:10万円/月(USD 665.77) Standard:30万円/月(USD 1997.32) |
※料金の計算に使用した条件は以下の通り。ものによっては選べないものもあったのでざっくりです。正確な条件は後述のキャプチャをご参照ください。
- リージョン:Tokyo
- 処理方式:バッチ
- DPUs:2 (=小規模環境)
- 稼働時間:月180時間
3大クラウドについては料金計算ツールが出ているので、自分の案件で正確に見積りがしたい方はご参照ください。
Google Cloud 料金計算ツール
https://cloud.google.com/products/calculator-legacy
AWS 料金計算ツール
https://calculator.aws/#/addService
Azure 料金計算ツール
https://azure.microsoft.com/ja-jp/pricing/calculator
なお、trocco はノーコードでエンジニアがいなくても ETL を組めるツールです。導入に時間をかけたくない、データの加工や流し先もシンプルで頻度も少ない、という場合はマッチすると思います。
料金計算ツールのキャプチャ
Google Cloud(Dataflow)
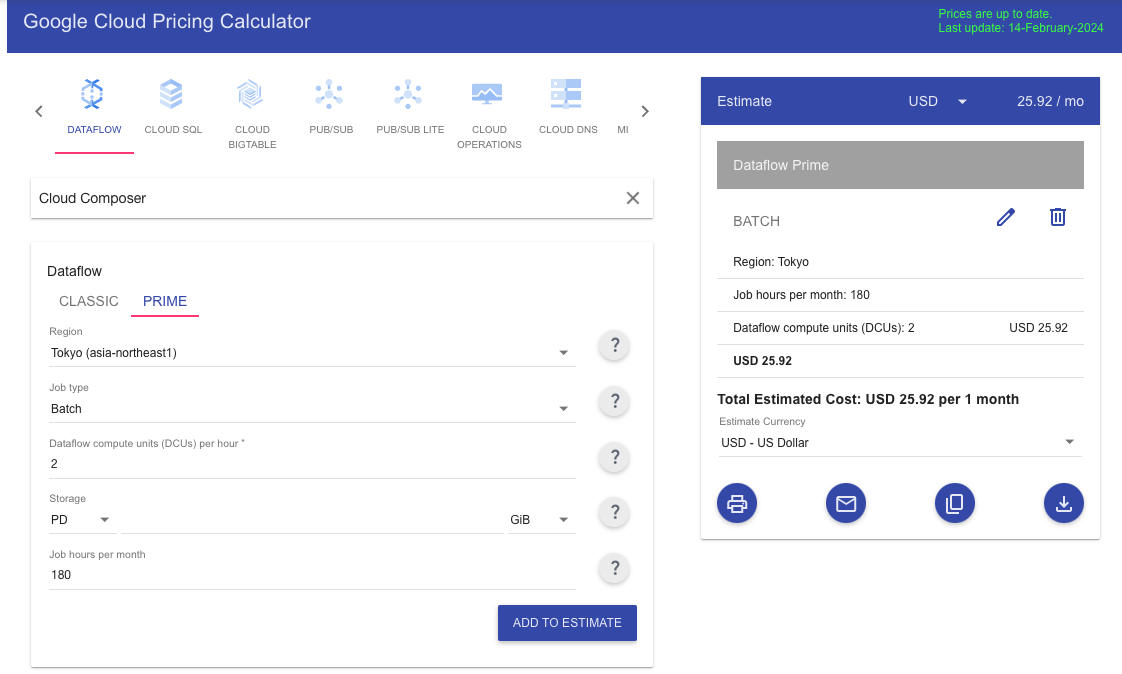
Google Cloud(Cloud Composer)
Google Cloud(Dataproc)
AWS(Glue ETL jobs and interactive sessions feature)
Azure(Data Factory)
Apache Beam、Apache Airflow、Apache Spark の違い
Apache Beam、Apache Airflow、Apache Spark はデータ処理・管理に使えるオープンソースのフレームワークですが、それぞれ目的が異なります。
<Apache Beam>
Apache Beam はバッチとストリーミングの両方を扱え、様々なバックエンド(例えばApache SparkやApache Flink、Google Cloud Dataflowなど)でデータ処理パイプラインを実行するために使用されます。
<Apache Airflow>
Apache Airflow はタスク間の依存関係を定義し、複雑なワークフローを管理します。要はワークフロー管理システムで、主にデータパイプラインのスケジューリング、監視、再試行などに使用されます。
<Apache Spark>
Apache Spark は大規模なデータ処理に特化した分散コンピューティングシステムで、データをメモリ(RAM)上で処理することで高速化を図ります。
バッチ、ストリーム、インタラクティブクエリなどの機能があり、主に分析や機械学習タスク、ビッグデータアプリに使用されます。
シンプルなAPIを提供し、Java、Scala、Python、Rなど複数の言語でデータ処理プログラムを作成できます。
という感じなので、これら3つのツールは連携して使用することもできます。
例えば、Airflowはデータパイプラインのスケジューリングとオーケストレーションに使用され、その中でApache Sparkのジョブをトリガーし、Apache Beamを使ってデータ処理のロジックを定義する、みたいなことができます。
まとめ
- 裏で動いている Apache 〜 のオープンソースは同じでも、各クラウドによって機能や料金が大きく異なる。
- Google Cloud は比較的価格も良心的
- AWS は少し高めだが1年間無料で使える機能もある
- trocco® はノーコードで手軽に作れる分、カスタマイズ性が比較的低く、料金は高い
API ARIMA AutoML Bard BigQuery Bing ChatGPT Cloud Endpoints Cloud Storage DWH EBPM GAS Generative AI Google Apps Script Google Cloud Google Form Google Workspace IT組織 Outlook PaLM PDF Python ReportLab selenium Statsmodels STL VertexAI Vertex Forecast スクラッチ セミナー ソトミル トレンド分析 トレーニング バッチ予測 世界は女性とデジタルが救う 女性活躍 技術 時系列データ分析 業務効率化 機械学習 特徴量エンジニアリング 生成AI 自動化 評価指標 需要予測