時系列データの季節トレンド成分分解は今やライブラリが充実し、誰でもお手軽にほぼ無料でできるようになりました。ただ、とりあえず分解してみても、グラフの解釈や、その結果の使い道など、ちょっと難しいかもしれません。
今回は、時系列データ初心者向けに、季節・トレンド成分分解でよくある「うまくいかないケース」とその原因、対処法について、具体例を交えながら解説したいと思います。
トレンド成分がガタガタしすぎる原因
複雑なデータだと、うまく成分分解できずに、トレンドがトレンドじゃない(涙)ってなりがちです。
例えば、コロナ期間を含む2021年9月1日〜2022年12月31日までの全国飲食チェーンの日別全店売上、という複雑な特性を持つ時系列データを、季節トレンド成分に分解してみます。
<seasonal_decompose を使った季節トレンド分解>
from statsmodels.tsa.seasonal import seasonal_decomposeimport pandas as pd #基本ライブラリーimport matplotlib.pyplot as plt #グラフ描写
result2 = seasonal_decompose(df['amount'], period=7)
# グラフ化
result2.plot()
plt.show()実行結果

まずグラフの見方ですが、一番上が入力データ(ここでは全国チェーン飲食店の日別売上サマリ)、二番目がトレンド、三番目が季節、一番下が残差です。残差というのは、入力データからトレンド成分、季節成分を差し引いた残りのことです。
つまり、日別で見た時、以下のように単純に足し合わせれば元の値に戻ります。
amount = Trend + Season + Resid
各グラフの左上にある「le8」というのは単位です。
上の例では、季節成分の桁が一つ少ない(影響が小さく見積もられてしまっている)ことがわかります。
また、トレンドもガタガタしすぎでトレンドとは言えない波形です。
<原因>
使っているクラス(seasonal_decompose)がデータの特性にフィットしていない。
<対処法>
代わりにSTLクラスを使う。
実は、複雑な構造を持つ時系列データの成分分解に適したクラスが別で用意されています。以下で解説します。
時系列成分分解の2つの手法(LOESS と 移動平均)
Statsmodels.tsa という、Pythonで無料で使える時系列分析のライブラリがあります。これは、データのトレンドや季節性、ノイズ(残差)を簡単に分析することができます。Statsmodels.tsa には、ARIMA、Exponential Smoothing、Holt-Winters、Seasonal ARIMA などの時系列分析手法が実装されています。
Statsmodels.tsa には2つのクラスがあります。
- STL:LOESS(ろえす)を使用した季節トレンド分解
- seasonal_decompose:移動平均を使用した季節トレンド分解
まぁ私の拙い言葉で説明するよりもグラフを見てもらった方がわかりやすいと思うので、それぞれでどんな違いが出るのか、とある全国飲食チェーンのデータを使ってやってみます。
STL(LOESS)を使った季節トレンド分解
今回分析するデータは、飲食店の売上なので、月単位ではなく週単位の周期とします。
日別データなので周期が週単位なら period=7 です。rebustはTrueにするとトレンド成分が滑らかになります。
from statsmodels.tsa.seasonal import STL
import pandas as pd #基本ライブラリー
import matplotlib.pyplot as plt #グラフ描写
# STL分解
result1=STL(df['amount'], period=7, robust=True) result1 = result1.fit()
# STL分解結果のグラフ化result1.plot()
plt.show()実行結果

単位はどの成分も「le8」なので、極端にある成分にだけ依存しているというわけでも無いので、まずまずの良い感じに分解できていそう。
ただ、トレンド成分がまだガタガタしすぎ&最後右肩上がりになってしまっており、その分の帳尻合わせが季節成分のマイナス値で調整されてしまっています。
STLクラスでは色々オプションが設定できて、トレンドの長さも指定できる(なぜか奇数のみ)ので、これを月ごと(trend=31)にしてみます。
from statsmodels.tsa.seasonal import STL
import pandas as pd #基本ライブラリー
import matplotlib.pyplot as plt #グラフ描写
# STL分解
result1=STL(df['amount'], period=7, trend=31, robust=True) result1 = result1.fit()
# STL分解結果のグラフ化result1.plot()
plt.show()実行結果
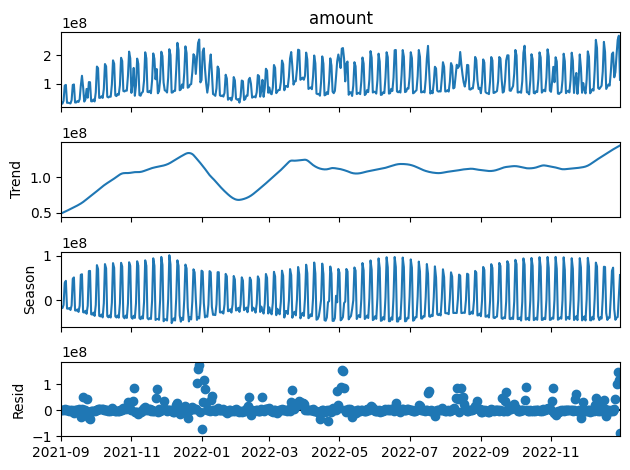
先ほどよりもトレンドらしく滑らかになりました。でも、最後ピヨっと右肩上がりになってしまっているのが気になりますね。
trendの値を大きくするほどトレンド成分は直線に近づいていきます。
trend=93(3ヶ月)の場合
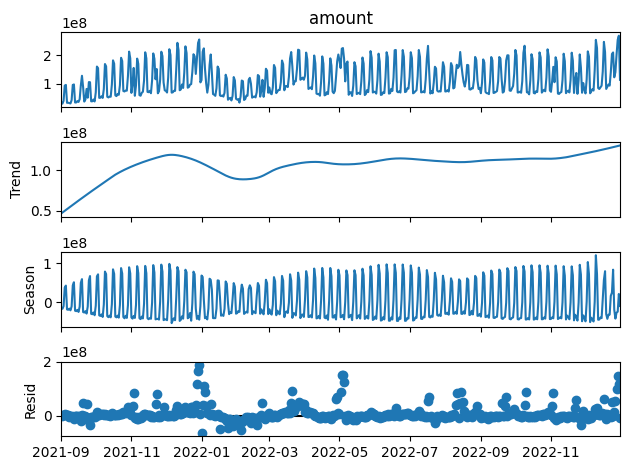
ひとまず、こんなところでしょうか。
考察
下の図は、日別の飲食チェーン全店売上サマリ(青い折れ線グラフ)に、コロナの影響を受けた店舗数(緑の棒グラフ)をプロットしたものです。
「コロナの影響を受けた」店舗数というのは、「その日、まん延防止、あるいは緊急事態宣言が発令されていた都道府県」に属する店舗の数です。

緑が集中している期間は、売上が凹んでいるのがわかります。
次に、先ほどの2つの結果を並べてみます。STLはトレンドを月(31日)とした場合のものを採用しています。
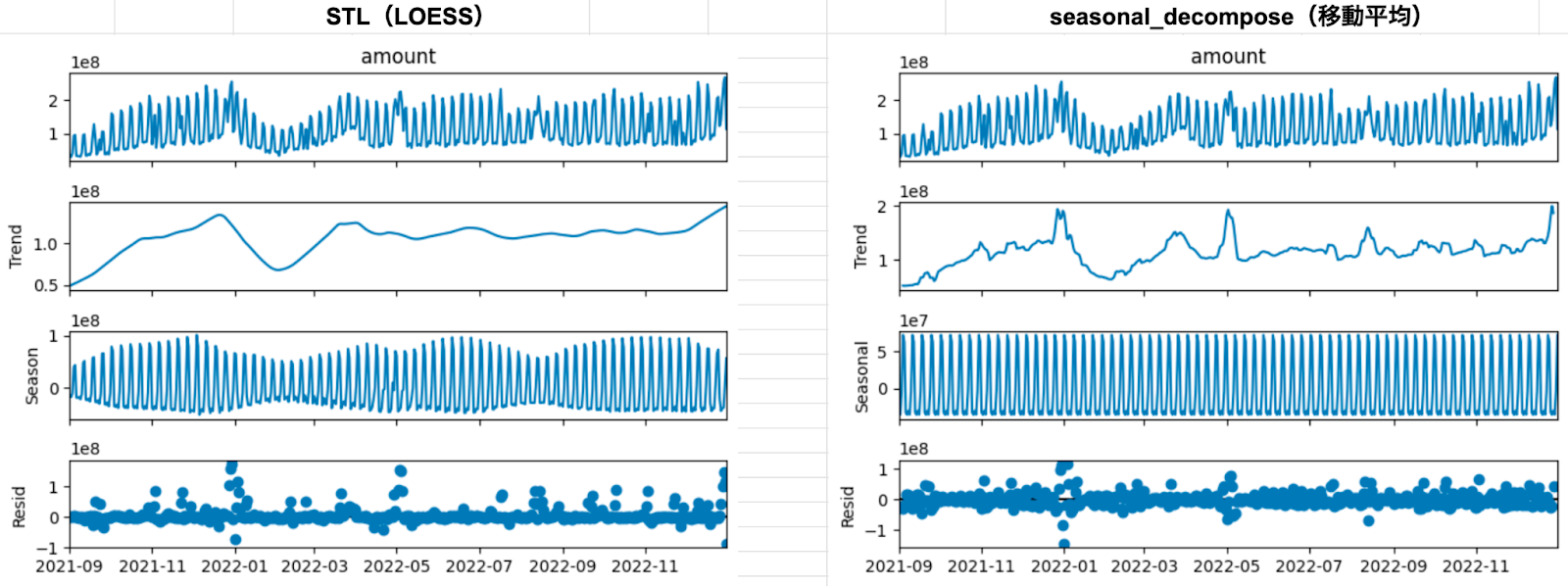
STL(LOESS)による季節トレンド分解は、先ほども述べたようにちょっと惜しいですね。季節性の振幅が一定でないため、トレンド成分だけでなく、季節成分にもちょっとコロナが混じっちゃってる感じです。他のオプションで調整すればもっと良くなるかもしれませんが、この記事ではここまでとします。
一方、seasonal_decompose(移動平均)による季節トレンド分解では、コロナの影響はトレンド成分にのみ効いているっぽい。ですが、トレンド成分に明らかに他の要因も効いてしまっており、うまく分解できているとは言いにくいです。
ちな、LOESS(ろえす)と移動平均の違いはこんな感じ。
| LOESS(ろえす) | 移動平均 | |
| 特徴 | 局所的なトレンドを把握 | 全体的なトレンドを把握 |
| ノイズの多いデータへの適合性 | 高い | 低い |
| トレンドが変化するデータへの適合性 | 高い | 低い |
結果から見ても、複雑な時系列データは、やはりLOESSの方がフィットやすかったのかなという感じです。
他にも、BigQueryMLのARIMA PLUSモデルなど簡単に試せるものはたくさんあります。しかし、ライブラリやツールによってクセがあり、同じデータでも結果はかなり変わってきます。
一つのツールだけではなく、成分分解したい時系列データに適したものは何か、ある程度と選定するのは重要だと思います。
この記事が、その一助になれば幸いです。
まとめ
- 時系列データの季節トレンド成分分解はPythonライブラリを使って無料で簡単にできる
- 複雑な時系列データは STL(LOESS)で成分分解する方がいい
- シンプルな時系列データは seasonal_decompose で成分分解する方がいい