時系列データの成分分解とは、時系列データを、トレンド、季節性、残差の 3 つの成分に分解する手法です。予測の精度を向上させる、異常検知を行うなどの目的で行われます。
今回は、時系列データの成分分解を以下2つの手法(ツール)で比較して、どっちが上手に分解してくれるか検証してみました。
時系列データの成分分解
繰り返しになりますが、時系列データの成分分解とは、時系列データを、トレンド、季節性、残差の 3 つの成分に分解する手法です。
- トレンド:時系列データの長期的な傾向を表す成分。例)経済成長率や人口増加率など
- 季節性 :時系列データの周期的な変動を表す成分。例)気温や売上高など
- 残差 :トレンドと季節性の影響を取り除いた成分。 例)天候や突発イベントなど
<主な手法>
| 手法 | 加法型成分分解 | 減法型成分分解 | STL 分解 | ホモセカスティック分解 |
| 分解方法 | 加算 | 減算 | 局所回帰※ | 分散と共分散の変化 |
| トレンド推定 | 線形モデルや非線形モデル | 線形モデルや非線形モデル | 局所回帰※ | 線形モデルや非線形モデル |
| 季節性推定 | 周期性 | 周期性 | 局所回帰※ | 周期性 |
| 残差分析 | なし | なし | あり | なし |
| 適用データ | トレンドと季節性の成分が明確に分離されているデータ | トレンドと季節性の成分が明確に分離されているデータ | トレンドと季節性の成分が複雑に絡み合っているデータ | 分散と共分散が時間の経過とともに変化しないデータ |
| 計算量 | 比較的少ない | 比較的少ない | 比較的多い | 比較的少ない |
| 特徴 | シンプル | シンプル | 複雑 | シンプル |
※局所回帰とは、時系列データの近傍の値を用いて、その点の値を予測する手法
今回は、中でもよく使われる加法型成分分解と、STL 分解でそれぞれ対決しました。
STL 分解 → statsmodels:Pythonの統計分析ライブラリ
加法型成分分解 → BigQueryML:BigQuery上で機械学習モデルを作成、評価、実行できるGoogle Cloudのプロダクト
Python の statsmodels を用いたSTL分解
お手軽に、Colab Notebooks を使って BigQuery のデータを加工していきます。
データ読み込み
# BigQueryのクエリ結果を読み込み(ジョブIDは各自書き換えてください)
job = client.get_job('bquxjob_XXXXXXXXXXXXXXXXX') # Job ID
print(job.query)データフレームに加工(売上のみ抽出、日付をインデックスにする)
import datetime
import pandas as pd
import numpy as np
dt = pd.to_datetime(results['business_datetime'], format='%Y-%m-%d %H:%M:%S')
am = np.float64(results['amount'])
df_multi = pd.DataFrame({'dt': dt,
'amount': am})
df = df_multi.set_index('dt')df = df.sort_index()
df['amount'].head()<出力>
dt
2021-11-01 68610999.0
2021-11-02 100146126.0
2021-11-03 155364907.0
2021-11-04 58561014.0
2021-11-05 94752159.0
Name: amount, dtype: float64
STL分解を実行
# ライブラリーの読み込み
import pandas as pd #基本ライブラリー
from statsmodels.tsa.seasonal import STL #STL分解
import matplotlib.pyplot as plt #グラフ描写
# STL分解
stl=STL(df['amount'], period=7,trend=31,robust=True) #週毎
stl_series = stl.fit()
# STL分解結果のグラフ化
stl_series.plot()
plt.show()<出力>
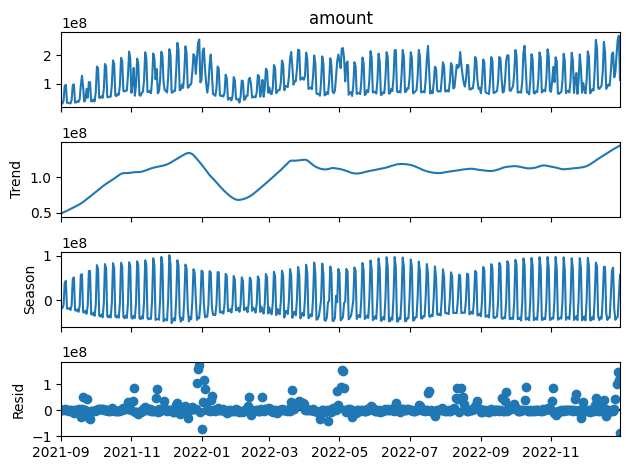
なお、CSV化してダウンロードするコードは以下。
df_stl = pd.DataFrame({
'observed': stl_series.observed,
'resid': stl_series.resid,
'seasonal': stl_series.seasonal,
'trend': stl_series.trend,
'weights': stl_series.weights
})
df_stl.to_csv("df_stl.csv")別記事でSTL分解した時系列データを成分ごとに予測して足し合わせる検証を行ったのですが、採用したのはこちらのデータになります。
<リンク(予定)>
BigQueryML(ARIMA PLUSモデル)による加法型成分分解
BigQuery ML の ARIMA PLUS モデルは、時系列データの成分分解を行うことができます。今回、BigQueryMLで行った ARIMA_PLUS モデルを用いた EXPLAIN_FORECAST は、加法型成分分解です。
ARIMA PLUS モデルによる成分分解は、次の手順で行われます。
- 時系列データを ARIMA モデルで予測
- 予測結果から、トレンドと季節性の成分を抽出
- トレンドと季節性の成分を差し引いて、残差を計算
クエリは以下の例を参考にしてください。
--モデル作成
CREATE OR REPLACE MODEL `プロジェクト名.データセット名.モデル名`
OPTIONS(MODEL_TYPE='ARIMA_PLUS',
time_series_timestamp_col='business_day',
time_series_data_col='amount',
time_series_id_col='store_cd') AS
SELECT
business_day,
amount,
store_cd
FROM
`プロジェクト名.データセット名.元データ用テーブル名`
;
-- 成分分解
CREATE OR REPLACE TABLE `プロジェクト名.データセット名.結果格納用テーブル名` AS
SELECT
*
FROM
ML.EXPLAIN_FORECAST(MODEL `プロジェクト名.データセット名.モデル名`,
STRUCT(31 AS horizon, 0.95 AS confidence_level))成分分解の結果をグラフ化したものが下図になります。
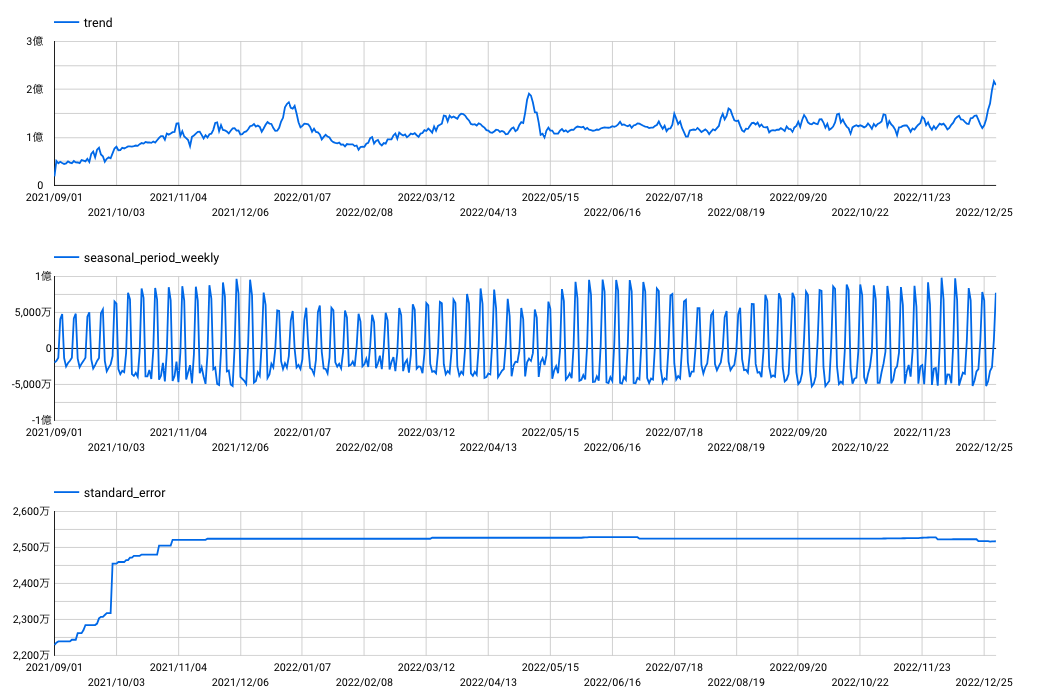
うーむ、、、トレンドがトレンドになってない。(トレンドはギザギザしないべき!)
ということで、ひとまず勝者は statsmodels でした。
BigQueryML 敗因の考察
加法型成分分解はシンプルすぎて、今回の複雑な時系列データ(飲食チェーンの売上)の分解には適さない、という点に尽きると思われます。
加法型成分分解ではトレンドと季節性の成分を線形モデルや非線形モデルを用いて推定することが多いのですが、今回のBigQueryMLの ARIMA PLUSモデル では線形モデルと非線形モデルを組み合わせたもので、非定常な時系列データにも適応できる、、、はずでした。
所詮は線形モデルの延長線上、ということでしょうか。
線形モデル(加法型成分分解)と局所回帰(STL分解)の違いは、予測対象の点の近傍の値を用いて予測を行うかどうかです。線形モデルは、時系列データ全体の値を用いて予測を行いますが、局所回帰は、予測対象の点の近傍の値を用いて予測を行います。
そのため、局所回帰は、予測対象の点の値の変化をより正確に捉えることができます。
計算量が多い分、局所回帰の方が正確であり、複雑な時系列データの場合は分解精度の差がより顕著に現れてしまうのだと思います。
ちなみに、同じ加法型成分分解でも、ベイズ統計モデルクラスを用いる成分分解のツールもあり、以前、個人的にも少し触ったことのある Prophet などが(Google が開発した時系列データの予測モデル)挙げられます。
Prophet vs statsmodelsのSTL なら勝敗はわからないかも、と思いました。そのうち、余力がある時に検証するかも。
まとめ
- 今回読者に覚えてもらいたい技術を2~4点くらいにしぼって箇条書き
- 時系列データの成分分解の主な方法に、加法型成分分解と、STL分解がある
- 加法型成分分解は、トレンドと季節性の成分を線形モデルや非線形モデルで推定する
- STL分解は、トレンドと季節性の成分を局所回帰で推定する
- BigQueryMLのARIMA PLUSのEXPLAIN_FORECASTは加法型成分分解なので、複雑な時系列データには適さない