今回は、Vertex Forecast を使ったマニアックな検証をご紹介します。
題して、、、
時系列データの目的変数をSTL分解(トレンド、季節性、残差に分解)して、各成分についてモデルを作って時系列予測したら、何もせずに1モデルで時系列予測した場合と比べて精度が上がるのか?
です。
ちなみに結論からいうと、何もせずに1モデルで予測した方が良い、でした(悲)
精度がすごく良くなってみんなに褒められる夢まで見たのでショックでしたが、STL分解してから各成分を予測して最後足し合わせる、という方法は AI 予測界隈では一般的なアプローチの一つなので、ご紹介も兼ねて記事にします。
飲食店における店舗売上と、各特徴量の因果関係の仮説立て
まずは仮説を立て、仮説が正しいかを検証します。
検証に使う題材は、「全国展開している外食チェーンの日別店舗別売上の予測」とします。主な特徴量とその因果関係は以下のような図になるとします。図の赤い四角が、入力として使える「特徴量」です。
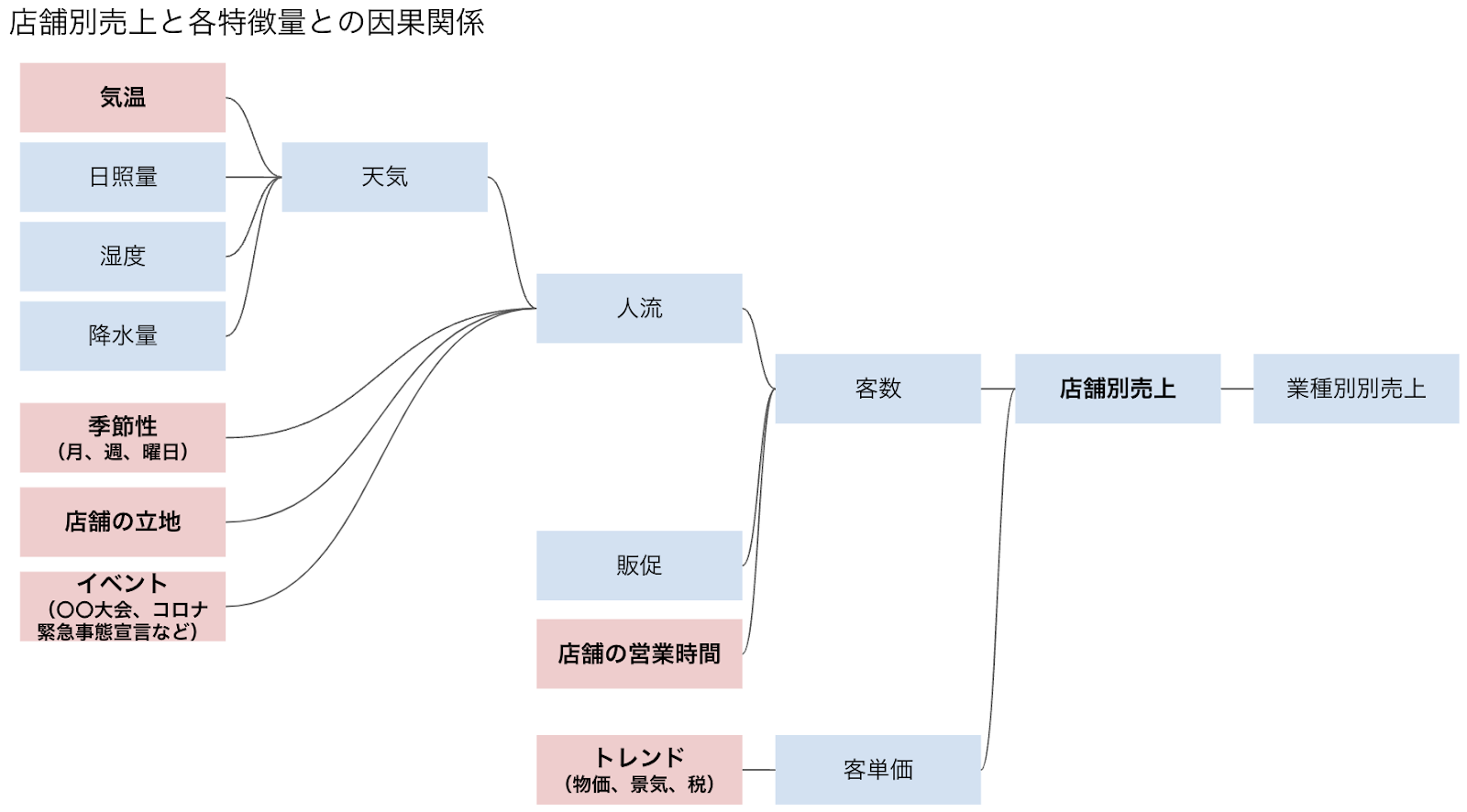
単純化すると、日別売上は1日あたりの 客数 × 客単価で表されます。
<客数>
客数は、その立地における「人流」、その店舗の「営業時間」、あとはその他の要因「販促」などで決まります。当たり前ですが、都心の駅前でランチタイムから営業している店舗と、田舎の国道沿いにある夜のみ営業の店舗ではベースとする客数平均が大きく異なります。販促も多少は影響しますが、特徴量からは除外します。※
※販促情報は数値化が難しく(これをやったら何人の客がくる、というものではない)、売上への影響も営業時間や人流に比べると軽微です。売上予測の特徴量に使うためには予測のための予測(売上予測のための販促数値の予測)をする必要があり、ここで精度が悪いと本丸の売上予測のノイズになってしまうため、大抵の場合は予測が当たらない時の原因分析などで使うのが吉。
人流
その日の天気、そして季節性(春夏秋冬、平日休日や曜日など)、立地、イベント※に左右されます。
※ここでいうイベントは、クリスマスや年末年始、お盆、GWなどの国民的イベントや、コロナによる緊急事態宣言、数十万人以上が集まる大規模な花火大会などが該当します。例えば、近所の小学校の運動会や歌手のコンサートなどは、販促と同じ理由から除外します。
天気(気象情報)
晴れ、雨、曇りなどのいわゆる「天気」は予報が当たりにくいため、予測因子として使うには不向きでした。「降水量」や「湿度」も予報自体の精度があまり高くないですが、「気温」と「日射量」は予報でもそれほどぶれません。日射量で晴れかそうでないか、を判断する手もありますが、本検証ではシンプルにするため気温のみ参照します。
<客単価>
全国チェーンにおける客単価は、おおむね景気と連動すると考えます。商品ラインナップや客層が劇的に変わる、ということはそうそうない前提。
厳密に考えると、注文した商品(メニュー)数×商品(メニュー)単価で決まりますが、ここまで細かくすると「客(年代、性別、人数etc..)」や「商品(メニュー)」の単位で考慮せねばならず複雑すぎるので、ひとまず、「時間あたりの売上÷時間あたりのレシート数」を実績と考えます。
日別売上は時系列データです。
仮説では、日別店舗別売上という時系列データを、STL分解でそれぞれ「トレンド」「季節性」「残差」の成分に分解した時、それぞれ以下の特徴量と連動します。
トレンド:客単価と連動
季節性:気温、曜日と連動
残差:イベント、店舗の営業時間と連動
仮説が正しければ、トレンド成分の予測、季節性成分の予測、残差の予測をそれぞれ別で行うことで、分解せずにそのまま予測させるよりも精度が上がるのではないか、というのが今回検証したいこと。
売上をトレンド、季節性、残差に分解(STL分解)し、各成分の予測を足し合わせる
やりたいことを図にまとめてみると、こんな感じです。
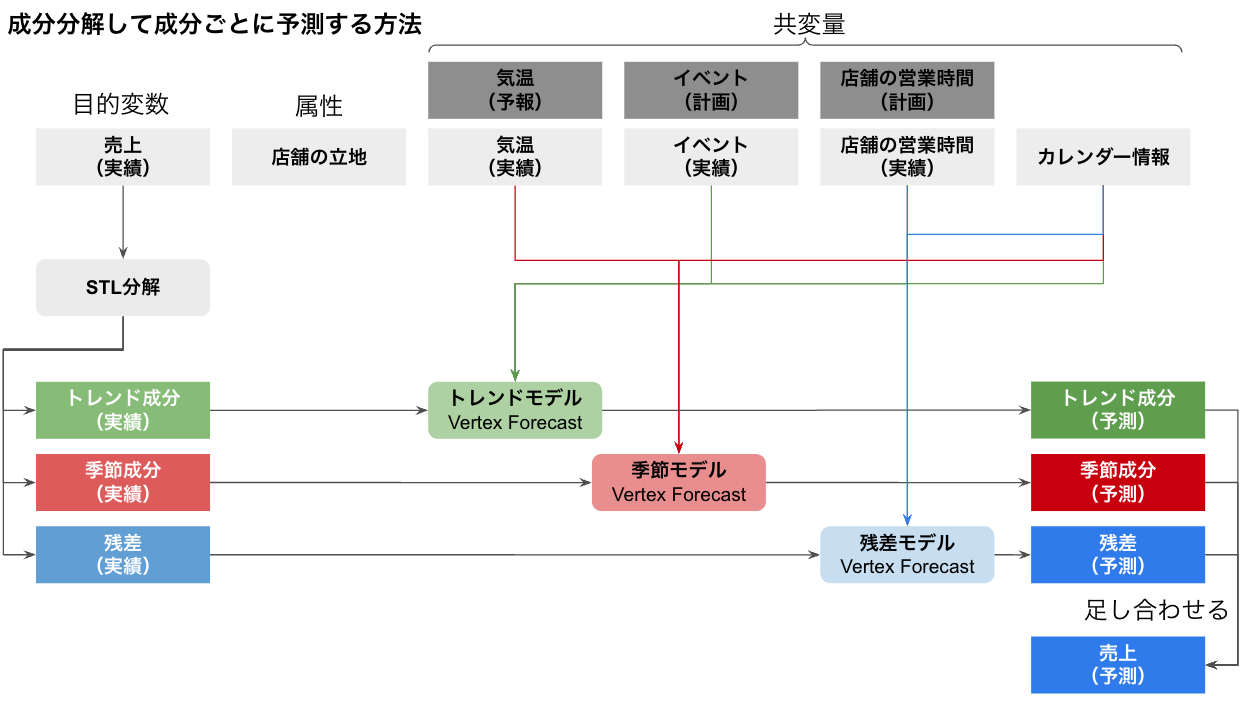
時系列データの目的変数の分析(STL分解)
↓
各成分と、各特徴量との連動を確認
↓
成分ごとに予測し、足し合わせ、結果を比較する
トレンド成分、季節成分、残差のそれぞれと連動する特徴量(説明変数のうち共変量)はどれか、そもそもあるのか、という問題です。
やってみないとわからないのでとりあえずやってみました。
時系列データ(2021/9〜2022/12の全店舗売上サマリ)の成分分解
早速、STL分解でそれぞれの成分に分解してみました。(STL分解の具体的な方法、コードは別記事にまとめてあるのでよかったらそっちも読んでいただけると嬉しいです)
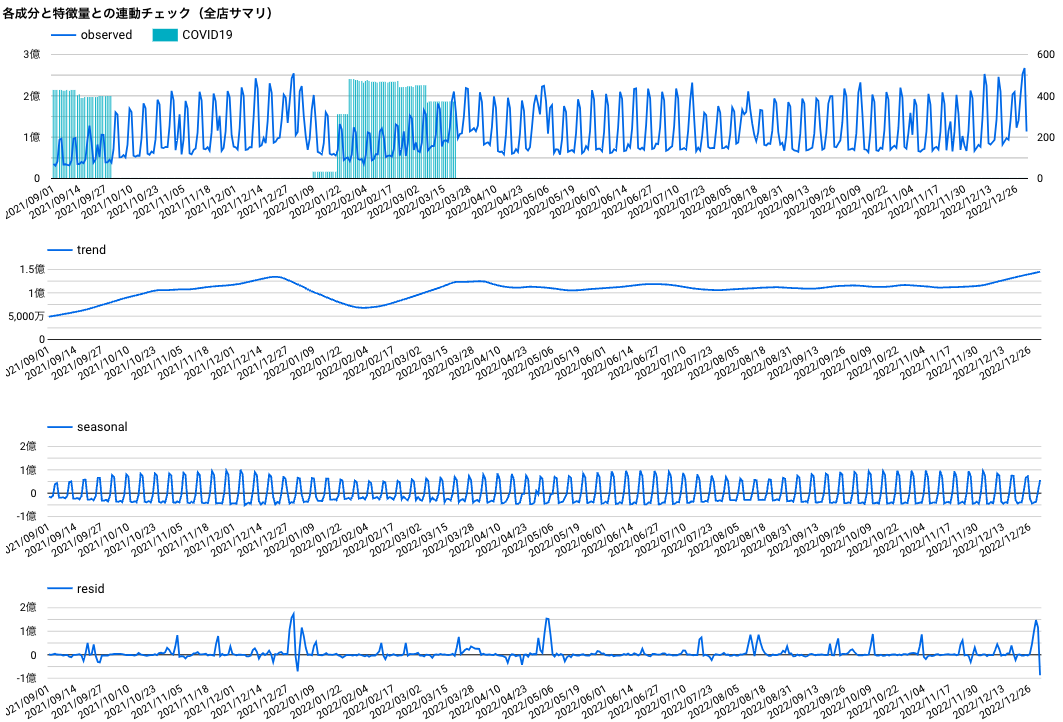
一番上が入力データである日別売上全店サマリ(緑の棒グラフはコロナの影響を受けた店舗数)、二番目がトレンド成分、三番目が季節成分、四番目が残差です。
残差というのは、入力データからトレンド成分、季節成分を差し引いた残りのことです。
つまり、日別で見た時、以下のように単純に足し合わせれば元の値に戻ります。
amount = Trend + Season + Resid
<トレンド成分>
トレンド成分は、コロナ期間(一番上の緑の棒グラフ)と連動して凹んでいることがみて取れます。
トレンド成分の予測モデルに使う特徴量は、以下で良さそうです。
- トレンド成分(実績)
- コロナの影響を受けた店舗数(イベント実績)
一応、相関係数をチェックしてみると、ちゃんと負の相関がみられました。

<季節成分>
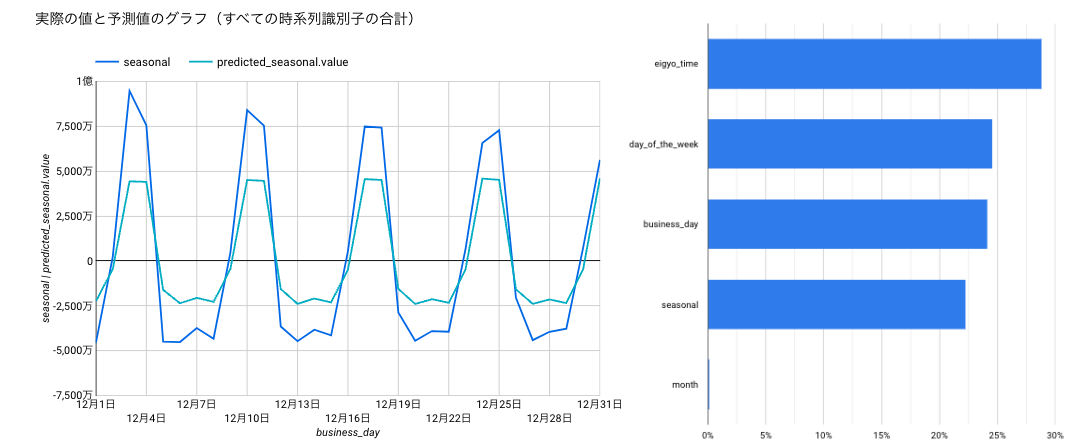
次に、季節成分ですが、ギザギザしているのは平日の売上は小さく、休日祝日の売上は大きいためです。この辺は営業時間が関係していると推測できます。(休日のみランチもやる店舗が多い=休日は営業時間が長い)
また、全体的に春秋(4〜6月と10〜12月)は振幅が大きく、夏冬(1〜3月と7〜9月)は振幅が小さいように見えます。春秋は大きくなって夏冬で小さくなるといえば、気温差。なので、気温差を表す指標を作れば、学習データに使えそうです。

まとめると、季節成分の予測に使えそうな特徴量は以下の通り。
- 季節成分(実績)
気温の寒暖差を表す指標(前日との気温差など)- 営業時間
- カレンダー情報(曜日)
なぜ気温に取り消し線が引かれているかというと、相関係数を確認したところ(下表)、気温差がほぼ0、最高気温も0.01と、相関が見られなかったから。微妙ですが、営業時間はやや相関あり。

<残差>
最後に残差ですが、ざっとみた感じでは大きく揺れている日は国民の祝日であることが多そうでした。なので、以下2つで良さそう。
- 残差成分(実績)
- カレンダー情報(祝日)
各成分の予実と、モデルの特徴量の重要度
各成分の予実と、モデルの特徴量重要度を並べます。
特徴量重要度とは、モデルトレーニング時に Vertex Forecast が各特徴量について予測に対する重要度を評価した数値です。
トレンド
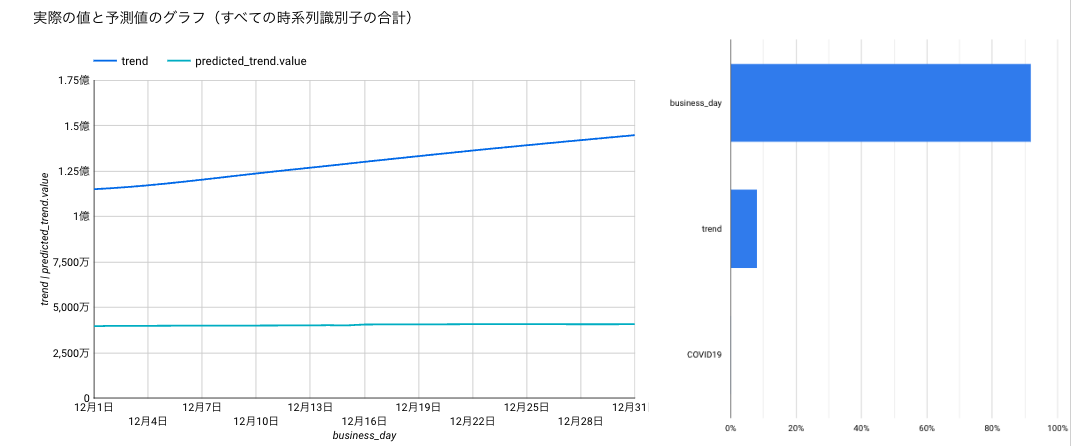
季節性
残差
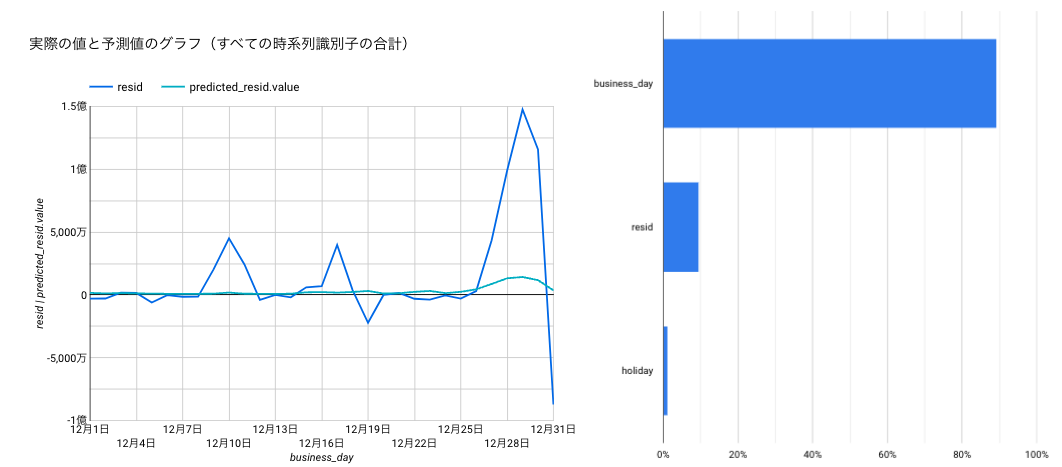
青線が実績値、緑線が予測値なのですが、いずれも乖離が大きく使えそうにありません。。すでに結果は見えていますが、一応、各成分の予測値を足し合わせたものと、何もせずにそのまま予測させたものの比較をグラフ化します。
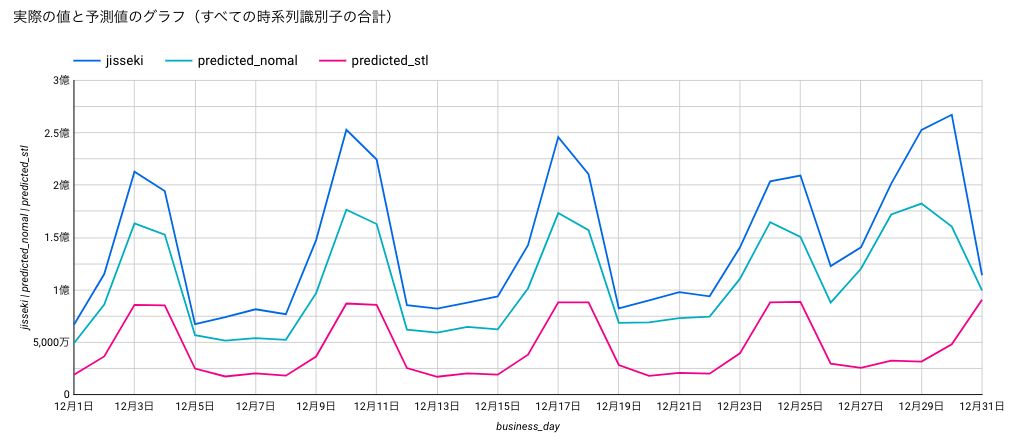
青が実績、緑が何もせずに普通にVertex Forecastで予測したもの、赤がSTL分解して各成分を予測して足し合わせたものです。めちゃくちゃ頑張ったのに赤が全然ダメですごく悲しい。
ちなみに、この結果に関してGoogle Cloudサポートに問い合わせた結果、以下のような回答でした。
Typical usage of the system involves forecasting sales directly, rather than forecasting components of the STL decomposition.
システムの一般的な使用法には、STL 分解のコンポーネントを予測するのではなく、売上を直接予測することが含まれます。
Google Cloud 技術サポートの回答より抜粋
他のAutoML系でも言えることかもしれませんが、Vertex Forecast に関してはいたずらに加工せず、直接売上データを予測させてた方が良いようです。